-
[SpringBoot] 6주차 페이지네이션(Pagination), N+1 문제 해결Study/SpringBoot 2026. 5. 7. 15:43
지난 주차에 인증/인가 로직을 구현하여 게시판의 뼈대를 완성했다. 이번 주차의 핵심 과제는 데이터 최적화다. 게시글이 10만 개가 넘어가는 상황에서 전체 데이터를 한 번에 조회하면 서버 메모리와 네트워크에 엄청난 부하가 걸린다.
이를 해결하기 위해 데이터를 필요한 만큼만 잘라서 보여주는 페이지네이션(Pagination)을 도입하고, 게시글 목록과 작성자 정보를 함께 가져올 때 발생하는 ORM의 고질적인 성능 저하 원인인 N+1 문제를 해결한 과정을 정리한다.이번 주차 공부 내용
- 게시글 목록 API 작성 -> 페이지네이션 구현
- N+1 문제 해결
📌 N+1 문제는 무엇이며, 왜 발생하는가?
데이터베이스와 ORM(JPA)을 다룰 때 가장 주의해야 할 성능 저하 원인이 바로 N+1 문제이다.
연관 관계가 설정된 엔티티를 조회할 때, 조회된 데이터 갯수(N)만큼 연관된 데이터를 조회하기 위한 추가 쿼리가 발생하는 현상이다.
예를 들어, 게시글 10개를 가져오기 위해 1번의 쿼리를 날렸는데, 각 게시글의 '작성자 이름'을 알기 위해 회원 테이블을 10번 더 조회하게 되어 총 11번(1 + 10)의 쿼리가 실행되는 비효율적인 상황을 의미한다.발생하는 근본적인 이유
- JPA의 프록시(Proxy)와 지연 로딩(Lazy Loading): 게시글(Post) 엔티티를 조회할 때, 성능 최적화를 위해 연관된 회원(Member) 데이터는 진짜 객체가 아닌 가짜 객체(프록시)로 채워둔다. (이것이 지연 로딩이다.)
- DTO 변환 시점의 데이터 접근: 이후 응답을 만들기 위해 post.getMember().getName() 코드가 실행되는 순간, JPA는 비어있는 프록시 객체를 실제 데이터로 채우기 위해 그제야 DB에 단건 조회 쿼리(SELECT)를 날리게 된다.
- 반복문과의 결합: 게시글 10개가 담긴 리스트를 순회하며 .getName()을 10번 호출하게 되므로, 매 호출마다 DB 쿼리가 발생하여 결국 N+1 문제가 터지는 것이다.
기능 구현 Flow(코드 로직)
Step 1. 페이지네이션 전용 응답 객체(DTO) 설계: 프론트엔드를 배려한 데이터 구조
게시글이 10만 개가 넘어갈 때 전체 데이터를 한 번에 응답하는 것은 서버와 네트워크에 치명적이다. 프론트엔드에서 하단의 페이지 번호 [1] [2] [3]을 렌더링할 수 있도록 게시글 배열뿐만 아니라 전체 페이지 수 등의 메타데이터를 함께 반환하는 전용 DTO를 설계했다.- Client Request: 클라이언트가 GET /api/posts?page=1&size=10 형태로 목록 조회 API를 호출한다.
- Data Extraction: 서버는 파라미터에 맞게 데이터베이스에서 데이터를 끊어와 Page<Post> 객체 형태로 획득한다.
- Entity to DTO Conversion: 순수 엔티티가 담긴 Page<Post> 객체를 팩토리 메서드(from)로 넘겨받는다.
- Metadata Assembly: 내부의 게시글 엔티티들을 PostResponseDto로 매핑하고, getTotalPages(), getTotalElements() 등을 추출하여 하나의 완벽한 페이징 응답 객체로 조립한다.
// PostPageResponseDto.java @Getter @Builder public class PostPageResponseDto { private List<PostResponseDto> postList; // 게시글 목록 private int totalPages; // 전체 페이지 수 private long totalElements; // 전체 게시글 수 // Page<Post> 객체를 받아서 DTO로 변환해 주는 팩토리 메서드 public static PostPageResponseDto from(Page<Post> postPage) { return PostPageResponseDto.builder() .postList(postPage.getContent().stream() .map(PostResponseDto::from) .collect(Collectors.toList())) .totalPages(postPage.getTotalPages()) .totalElements(postPage.getTotalElements()) .build(); } }프론트엔드는 이 구조화된 데이터를 바탕으로 게시글 목록과 페이지네이션 바를 완벽하게 그려낼 수 있다.
Step 2. N+1 문제 해결 (Fetch Join): 터미널 쿼리 폭격 막기
목록을 조회할 때 각 게시글의 '작성자 이름'을 함께 반환해야 한다. 이때 1번의 게시글 조회 쿼리 이후, 10개의 글마다 작성자를 알기 위해 회원 테이블을 10번(N번) 추가 조회하게 되는 ORM의 고질적인 성능 저하, N+1 문제가 발생한다.- Problem Recognition: 기본 제공되는 findAll()을 사용하면 지연 로딩(Lazy Loading)으로 인해 N+1 문제가 발생하여 서버 성능이 급감한다.
- Custom Query (Repository): 이 현상을 방지하기 위해 PostRepository에 @Query 어노테이션을 사용하여 직접 JPQL을 작성한다.
- Fetch Join Application: JOIN FETCH 문법을 적용하여 게시글을 가져올 때 연관된 회원(Member) 정보까지 단 한 번의 쿼리로 메모리에 끌어온다.
- Count Query Separation: 복잡한 쿼리와 페이징을 함께 쓸 때 JPA가 카운트 쿼리를 유추하지 못해 에러가 나는 것을 막기 위해 countQuery를 명시적으로 분리하여 작성한다.
// PostRepository.java public interface PostRepository extends JpaRepository<Post, Long> { // N+1 문제를 해결하기 위한 Fetch Join 쿼리 + 페이징 처리 @Query(value = "SELECT p FROM Post p JOIN FETCH p.member", countQuery = "SELECT count(p) FROM Post p") Page<Post> findAllWithMember(Pageable pageable); }이제 터미널을 지저분하게 도배하던 수십 개의 SELECT 쿼리가, 단 한 번의 깔끔하고 효율적인 JOIN 쿼리로 최적화된다.
Step 3. 목록 조회 API 완성 및 Transactional 읽기 전용 최적화
앞서 설계한 응답 객체와 N+1 방어 로직이 적용된 레포지토리를 바탕으로, 실제 클라이언트의 요청을 받아 처리하는 Controller와 Service 계층을 완성한다.- Parameter Parsing (Controller): @RequestParam을 사용해 URL에서 page와 size 값을 추출한다. defaultValue를 지정해 클라이언트가 값을 누락해도 서버가 터지지 않게 방어한다.
- Pageable Creation (Service): Spring Data JPA는 페이지 인덱스를 0부터 계산한다. 클라이언트가 넘긴 page 값에서 -1 처리를 하고, 최신 글이 상단에 오도록 ID 기준 내림차순(DESC) 정렬 조건을 넣어 Pageable 객체를 생성한다.
- Repository Call (Service): 생성된 Pageable 객체를 Fetch Join이 적용된 findAllWithMember() 메서드로 넘겨 DB 조회를 수행한다.
- Read-Only Optimization: Service 클래스 상단에 걸어둔 @Transactional(readOnly = true) 덕분에 해당 조회 메서드는 변경 감지(Dirty Checking) 작업이 생략되어 최상의 조회 속도를 낸다.
// PostService.java 중 일부 // [목록 조회] 페이지네이션 및 N+1 해결 적용 public PostPageResponseDto getPostList(int page, int size) { // 1. Pageable 객체 생성 (0페이지부터 시작하므로 page - 1 처리) Pageable pageable = PageRequest.of(page - 1, size, Sort.by(Sort.Direction.DESC, "id")); // 2. Repository 호출 (Fetch Join이 적용된 커스텀 메서드) Page<Post> postPage = postRepository.findAllWithMember(pageable); // 3. 엔티티 페이지를 DTO로 변환하여 반환 return PostPageResponseDto.from(postPage); } // PostController.java 중 일부 @GetMapping public ApiResponse<PostPageResponseDto> getPostList( @RequestParam(defaultValue = "1") int page, @RequestParam(defaultValue = "10") int size) { int validatedPage = Math.max(1, page); // 최소 1페이지 보장 PostPageResponseDto response = postService.getPostList(validatedPage, size); return ApiResponse.onSuccess(response); }스웨거를 통해 테스트를 진행하면 지정한 size만큼의 게시글 데이터와 작성자 이름, 그리고 페이징을 위한 메타데이터가 완벽한 JSON 형태로 반환됨을 확인할 수 있다.
코드에 사용된 문법(어노테이션) 및 객체 정리
Step 1. 페이지네이션 전용 응답 객체(DTO) 설계
핵심 코드: PostPageResponseDto의 팩토리 메서드// PostPageResponseDto.java @Getter @Builder public class PostPageResponseDto { private List<PostResponseDto> postList; // 게시글 목록 private int totalPages; // 전체 페이지 수 private long totalElements; // 전체 게시글 수 // Page<Post> 객체를 받아서 DTO로 변환해 주는 팩토리 메서드 public static PostPageResponseDto from(Page<Post> postPage) { return PostPageResponseDto.builder() .postList(postPage.getContent().stream() .map(PostResponseDto::from) .collect(Collectors.toList())) .totalPages(postPage.getTotalPages()) .totalElements(postPage.getTotalElements()) .build(); } }🔍 주요 어노테이션 및 객체 분석
- @Builder: 객체 생성을 위한 빌더 패턴 코드를 자동으로 생성해 준다. 파라미터의 순서에 구애받지 않고 어떤 필드에 어떤 값을 넣는지 직관적으로 파악하며 객체를 조립할 수 있게 해준다.
- Page<T> (인터페이스): Spring Data JPA에서 제공하는 페이징 전용 타입이다. 데이터베이스에서 조회한 실제 데이터 목록뿐만 아니라, 화면의 페이지 번호 렌더링에 필수적인 totalPages(전체 페이지 수), totalElements(전체 데이터 수) 등의 메타데이터를 내장하고 있어 매우 유용하다.
Step 2. N+1 문제 해결 (Fetch Join)
핵심 코드: PostRepository의 커스텀 쿼리 메서드// PostRepository.java public interface PostRepository extends JpaRepository<Post, Long> { // N+1 문제를 해결하기 위한 Fetch Join 쿼리 + 페이징 처리 @Query(value = "SELECT p FROM Post p JOIN FETCH p.member", countQuery = "SELECT count(p) FROM Post p") Page<Post> findAllWithMember(Pageable pageable); }🔍 주요 어노테이션 및 문법 분석
- @Query: Spring Data JPA가 메서드 이름으로 자동 생성해 주는 쿼리 대신, 개발자가 복잡한 조인이나 최적화를 위해 직접 작성한 JPQL(Java Persistence Query Language)을 실행하도록 지시할 때 사용한다.
- JOIN FETCH (JPQL 문법): 일반 SQL의 JOIN과 달리, 엔티티의 연관 관계를 바탕으로 대상 객체(Member)까지 한 번에 진짜 데이터로 영속성 컨텍스트에 끌어올리는(Eager) JPA 전용 최적화 문법이다. 지연 로딩(Lazy Loading)으로 인해 쿼리가 수십 번 추가로 나가는 N+1 문제를 원천 차단한다.
- countQuery 속성: Page 타입 객체를 반환할 때는 전체 데이터 개수 계산이 필수적이다. 복잡한 쿼리나 Fetch Join 사용 시 JPA가 카운트 쿼리를 자동으로 유추하지 못해 에러가 발생할 수 있으므로, 개수를 세는 쿼리를 명시적으로 분리하여 안전하게 알려준다.
Step 3. 목록 조회 API 완성 및 읽기 전용 최적화
핵심 코드: PostController의 목록 조회 API & PostService의 클래스 단위 트랜잭션// PostController.java @GetMapping public ApiResponse<PostPageResponseDto> getPostList( @RequestParam(defaultValue = "1") int page, @RequestParam(defaultValue = "10") int size) { int validatedPage = Math.max(1, page); PostPageResponseDto response = postService.getPostList(validatedPage, size); return ApiResponse.onSuccess(response); } // PostService.java (클래스 상단) @Service @RequiredArgsConstructor @Transactional(readOnly = true) // 읽기 전용 모드 적용 public class PostService { ... }🔍 주요 어노테이션 및 객체 분석
- @RequestParam: 클라이언트가 URL의 쿼리 스트링(?page=1&size=10)으로 보낸 파라미터 값을 추출하여 메서드의 매개변수로 매핑한다. defaultValue 속성을 지정해 두면 프론트엔드에서 파라미터를 누락하더라도 지정된 기본값이 들어가 서버 에러를 방지하는 방어막 역할을 한다.
- @Transactional(readOnly = true): 데이터베이스 트랜잭션을 읽기 전용 모드로 설정한다. 해당 범위 내에서는 JPA가 엔티티의 상태 변화를 감시하는 작업(Dirty Checking)을 생략하므로 메모리 사용량이 줄어들고 조회(SELECT) 속도가 극대화된다. 게시글 목록이나 단건 조회처럼 데이터를 변경하지 않는 서비스 클래스 상단에 필수적으로 붙여준다.
- Pageable (인터페이스): 클라이언트로부터 받은 페이지 번호, 데이터 개수, 정렬 조건(Sort)을 하나의 객체로 묶어 DB의 LIMIT와 OFFSET 쿼리로 간편하게 변환해 주는 페이징 처리의 핵심 파라미터이다. 클라이언트는 1페이지부터 호출하지만, JPA는 0페이지부터 시작하므로 서비스 단에서 page - 1 처리를 해주는 것이 중요하다.
실행 결과
저번 주차에 이어 로그인 상태로 게시글을 10개 이상(사진에서는 16개)을 생성한다.

게시글 생성 내용 
게시글 생성 16번 째 
새로 만든 페이지네이션 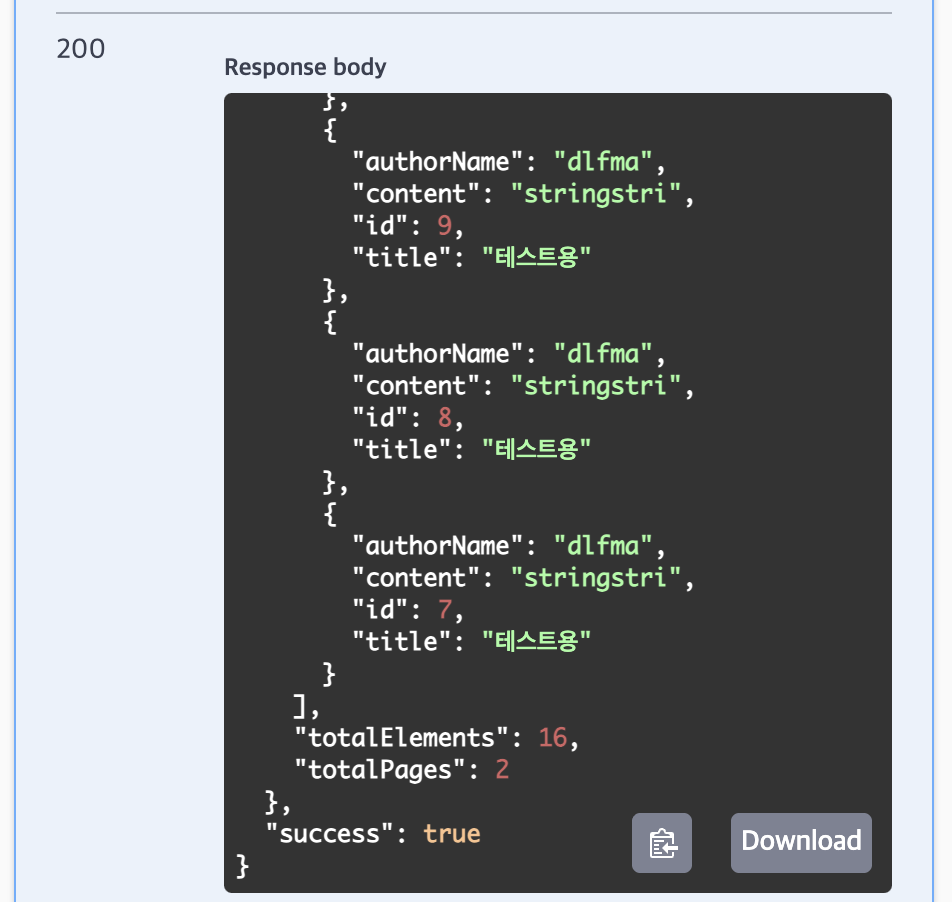
위 사진 total을 통해 정상 작동함을 알 수 있음
트러블 슈팅
Issue 1: 커스텀 쿼리(JOIN FETCH)와 Page 타입 혼용 시 발생하는 카운트 쿼리 누락 에러
[현상]
페이징 처리와 N+1 문제를 동시에 해결하기 위해 @Query를 작성하여 Page<Post>를 반환하도록 구현했다. 그러나 API 호출 시 정상적인 결과 대신 QueryExecutionRequestException (또는 InvalidDataAccessApiUsageException) 에러가 발생하며 서버가 응답하지 않았다.
[원인 분석]
일반적인 List<Post> 반환과 달리, Page<Post> 타입으로 반환받으려면 프론트엔드에 전달할 메타데이터(totalElements, totalPages 등)를 계산하기 위해 전체 데이터 개수를 세는 카운트(Count) 쿼리가 내부적으로 반드시 실행되어야 한다.
Spring Data JPA는 단순한 쿼리의 경우 카운트 쿼리를 자동 생성하지만, JOIN FETCH가 포함된 복잡한 커스텀 JPQL을 작성했을 때는 카운트 쿼리를 어떻게 생성해야 할지 스스로 판단하지 못해 예외를 던진 것이다.
[해결 방안 및 배운 점]
@Query 어노테이션 내부에 데이터를 조회하는 메인 쿼리와는 별개로, 데이터의 개수만 빠르게 세는 countQuery 속성을 직접 명시하여 해결했다.// 수정 전 (에러 발생: JPA가 카운트 쿼리를 만들지 못함) @Query("SELECT p FROM Post p JOIN FETCH p.member") Page<Post> findAllWithMember(Pageable pageable); // 수정 후 (해결: 카운트 쿼리 명시적 분리) @Query(value = "SELECT p FROM Post p JOIN FETCH p.member", countQuery = "SELECT count(p) FROM Post p") Page<Post> findAllWithMember(Pageable pageable);페이징을 구현할 때는 단순히 데이터를 자르는 것에 그치지 않고, 메타데이터 계산을 위한 카운트 쿼리의 비용과 최적화 메커니즘까지 명확하게 제어해야 프레임워크의 오작동을 막을 수 있음을 확인했다.
Issue 2: 게시글 목록 조회 시 발생하는 N+1 쿼리 폭격 문제
[현상]
페이징 로직을 처음 구현한 뒤 스웨거에서 API를 호출했다. 포스트맨이나 스웨거 화면에서는 10개의 게시글과 작성자 이름이 정상적으로 응답되어 기능상 문제가 없어 보였다. 하지만 인텔리제이의 실행 콘솔(Terminal)을 확인해 보니, select * from post 쿼리가 1번 실행된 직후 select * from member 쿼리가 10번이나 연속으로 도배되어 찍히는 현상을 발견했다.
[원인 분석]
기능은 동작하지만 성능을 갉아먹는 ORM의 고질병, N+1 문제였다.
Post 엔티티를 조회할 때, JPA는 성능 최적화를 위해 연관된 Member 데이터에 당장 쿼리를 날리지 않고 가짜 객체(프록시)를 채워두는 지연 로딩(Lazy Loading) 방식을 사용한다.
하지만 이후 응답 DTO를 만드는 과정에서 post.getMember().getName()을 호출하는 순간, 비어있는 프록시를 실제 데이터로 채우기 위해 그제야 DB에 단건 조회 쿼리를 날린다. 결과적으로 10개의 게시글을 순회할 때마다 매번 DB를 찌르게 되어 총 11번(1 + N)의 쿼리가 발생한 것이다.
[해결 방안 및 배운 점]
기본 제공되는 findAll() 메서드 대신, 연관된 엔티티를 한 번의 SQL 조인으로 미리 당겨오는 JPA 전용 문법인 JOIN FETCH를 사용하여 레포지토리를 수정했다.// 수정 전 (N+1 문제 발생) Page<Post> postPage = postRepository.findAll(pageable); // 수정 후 (단일 쿼리로 최적화) Page<Post> postPage = postRepository.findAllWithMember(pageable);이후 콘솔을 확인해 보니 단 한 번의 깔끔한 JOIN 쿼리만 실행되었다. ORM을 다룰 때는 API의 결괏값이 정상적으로 나온다고 안심할 것이 아니라, 실제 백그라운드에서 어떤 SQL이 생성되어 DB로 날아가는지 반드시 확인하는 습관을 들여야 한다는 것을 체감했다.
'Study > SpringBoot' 카테고리의 다른 글
[SpringBoot] 8주차 외부 API 연동, Redis 연결, 그리고 TTL(Time-To-Live) 설정 (0) 2026.05.28 [SpringBoot] 7주차 게시글 + 댓글 동시 저장 서비스 작성, 예외 케이스 적용, 인덱스 생성 (0) 2026.05.20 [SpringBoot] 5주차 JWT 인증/인가(회원가입 및 로그인) API 구현 (0) 2026.04.30 [SpringBoot] 4주차 게시판(수정, 삭제), 댓글(생성, 삭제) API 구현 및 Swagger 명세화 (1) 2026.04.02 [SpringBoot] 3주차 ERD 설계, Docker 연결 및 생성 조회 API 구현 (0) 2026.03.26